
作為2024年服貿會重要組成部分之一,國家衛生健康委員會百姓健康頻道(CHTV))定於9月13日在京舉辦“2024首都國際醫學大會的平行論壇——數智醫療與醫學人工智能創新論壇”,CHTV&醫學論壇網將為您帶來AI賦能醫療的係列報道,今天,我們特別聚焦騰訊優圖最新發表的一項突破性研究成果,探討大語言模型如何打破語言的桎梏 ,以實現其在中文醫療場景下的應用拓展。
導語:
作為2024年服貿會重要組成部分之一,國家衛生健康委員會百姓健康頻道(CHTV))定於9月13日在京舉辦“2024首都國際醫學大會的平行論壇——數智醫療與醫學人工智能創新論壇”,CHTV&醫學論壇網將為您帶來AI賦能醫療的係列報道,今天,我們特別聚焦騰訊優圖最新發表的一項突破性研究成果,探討大語言模型如何打破語言的桎梏 ,以實現其在中文醫療場景下的應用拓展。

吳賢博士
騰訊優圖天衍研究中心主任,專家研究員。主要研究方向為自然語言理解、深度機器學習、醫學大模型等。在Nature子刊,T-PAMI, NeurIPS, ACL, CVPR等國際頂級雜誌會議上發表文章一百餘篇,被引用超過4700次,有近50項美國和中國專利。
作為騰訊優圖實驗室天衍研究中心負責人,吳賢博士是醫療自然語言處理和醫學影像領域的領軍人物,專注於自然語言理解、深度機器學習和輔助診療係統等領域的研究。他帶領的團隊醫療大模型領域已取得了突破性進展,如醫學影像的精準解讀、疾病早篩及智能輔助診療係統等。
01
▼
語言障礙下的大型語言模型困境:開拓醫療AI新視野
近年來,隨著自然語言處理(NLP)技術的飛速發展,大型語言模型(LLM)在醫療健康領域的應用前景日益廣闊。它們通過大規模文本數據的預訓練,不僅掌握了強大的語言理解和生成能力,還編碼了廣泛的知識,以支持合理的醫學分析。然而,這些模型的開發和驗證主要依賴於以英語為中心的數據集,麵對非英語的醫療環境,它們的表現大打折扣。全球有超過7 000種語言,但用於訓練LLM的數據大約90%是英文的,非英語醫學語料庫更是稀缺,這種語言不平衡對LLM在非英語臨床場景中的應用構成了挑戰。
此外,現有的研究嚐試在訓練階段將臨床知識整合到LLM中,但這些嚐試往往局限於英語中心的LLM,缺乏跨語言環境的通用性,限製了它們在全球醫療保健領域的應用。同時,這些研究需要大量的高質量數據集和巨大的計算資源,對於資源有限的群體或國家來說並不實際。因此,如何在不同語言邊界內有效地整合各種類型的醫療知識到LLM中,仍然是一個未充分研究的問題。

2024年9月,聯合,共同在美國醫學信息學協會(AMIA)官方期刊J Am Med Inform Assoc發表了一篇題為的文章,提出了一種新穎的解決方案——開發一個能夠結合外部臨床知識源的上下文學習框架,以增強LLM在中文醫療背景下的表現。這一研究不僅針對了當前LLM在非英語環境中的局限,還可能為其他語言環境提供了一種切實可行的解決路徑。
02
▼
構建知識橋梁,提升模型性能:上下文學習框架的創新應用
少量樣本增強上下文學習(KFE)框架
本項研究的核心目標是通過構建一個全麵而深入的醫學知識庫和問題庫,引入一種創新的知識與,以此顯著提升LLM在處理非英語臨床問題時的性能。為了實現這一目標,研究團隊搜集並整合了53本權威的醫學書籍和高達381 149條醫學問題,以此構建出內容翔實的醫學知識庫和問題庫。這些資源不僅涵蓋了廣泛的醫學領域知識,也包含了豐富的臨床案例。
研究中,團隊選用了包括ChatGPT(GPT3.5)、GPT4、Baichuan2-7b和Baichuan2-13B在內的不同規模的LLM,並將它們置於中國國家醫學執照考試(CNMLE-2022)這一嚴格的真實臨床情境中進行評估。此評估不僅關注模型在整體考試中的表現,更深入地考察了它們在各個醫學科目以及臨床案例分析問題上的具體性能,從而全麵評價模型的醫學知識和臨床推理能力。

圖1 知識與少量樣本增強框架(KFE)的工作流程
主要評價指標聚焦於模型在CNMLE-2022中的總體性能,而次要評價指標則涉及到模型對不同醫學領域的掌握程度和對臨床案例的分析能力。通過這些細致的評價體係,研究旨在深入理解KFE框架如何影響LLM在醫學專業領域的應用效能,以及如何通過上下文學習優化模型的臨床推理過程(圖2)。這一研究設計不僅體現了方法學的嚴謹性,也展現了對模型性能全方位評估的深度考量。
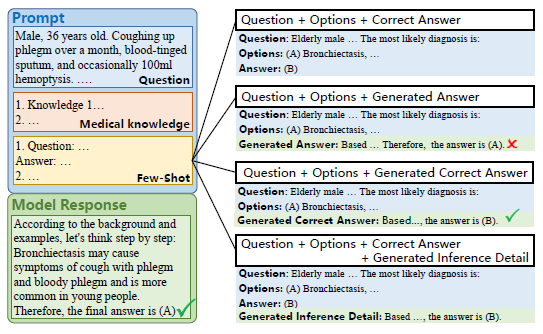
注:將檢索到的示例與問題和選項結合,以增強LLM的問題解決能力
圖2 少量樣本增強的四種策略
03
▼
知識融合顯著提升,模型表現超越人類平均水平
在本研究中,KFE框架的引入對LLM在臨床推理任務中的表現帶來了顯著提升。未經KFE框架輔助的ChatGPT在CNMLE-2022中的原始得分為,未能達到及格標準。然而,當ChatGPT結合KFE框架後,其得分飆升至,這一成績不僅達到了及格線,更超越了平均人類受試者的得分。更值得一提的是,,這一分數在所有參與測試的模型中表現最為突出(表1)。
表1 不同方法在CNMLE中的表現
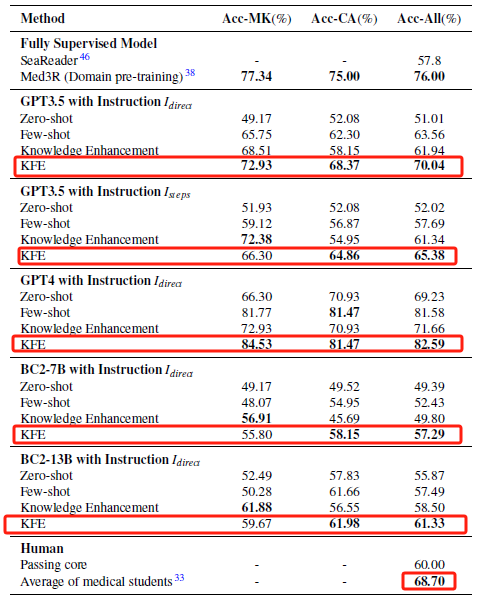
多維度分析模型表現,KFE框架優勢明顯
在KFE框架的輔助下,GPT4在處理MK問題時表現出色,準確率達到了84.53%,而在解決CA問題時,其準確率也達到了81.47%
進一步的分析表明,KFE框架對提升模型在醫學知識問題(MK)和臨床案例分析問題(CA)上的準確率具有顯著效果。(表1)。這一結果不僅凸顯了KFE框架在加強模型對醫學知識的深入理解和應用上的功效,也顯示了該框架在提升模型解答臨床問題時的精準度和適應性。KFE框架通過整合豐富的醫學背景知識和類似曆史問題的解決方案,為模型提供了更為精準的決策支持,使其在麵對複雜的臨床情境時能夠做出更加合理和準確的判斷。

注:A. 不同的少量樣本增強策略;B. 使用不同數量的示例進行少量樣本增強的效果;C. KFE使用不同數量的示例的效果;D. 不同指令策略對KFE效果的影響。
圖3 少量樣本增強策略的效果分析
通過KFE框架的輔助,即使是規模較小的模型也能在複雜的臨床推理任務中展現出與大型模型相媲美的能力
研究發現,不同規模的LLM,包括規模較小的Baichuan2-13B,均在KFE框架的輔助下通過了CNMLE-2022。Baichuan2-13B的成功,不僅驗證了KFE框架在低資源地區醫療教育和臨床實踐中的應用價值,更提供了一種成本效益高的解決方案,這對於提升這些地區醫療服務水平、縮小全球醫療差距具有深遠的意義。,這對於推動醫療資源的均衡分配和優化醫療質量具有重要的實踐價值。
作者指出,KFE框架的提出與驗證,不僅為非英語國家的醫療專業人員提供了一個強大的輔助工具,也為全球醫療教育和臨床實踐的數字化轉型提供了新的思路和方法。KFE框架的靈活性和可擴展性,使其能夠根據不同臨床需求定製化地整合專業醫學知識,進一步拓展了LLM在特定醫療領域的應用前景。此外,研究還指出了KFE框架在實際應用中可能麵臨的挑戰,如模型對特定醫學術語的理解和解釋能力,以及在不同醫療環境中的適應性等,這些都是未來研究需要進一步探討的問題。
04
▼
總結
這項研究提出了一種新穎的上下文學習框架KFE,通過整合多樣化的外部臨床知識源,顯著提升了LLM在中文醫學環境中的表現,不僅展示了KFE框架在提升模型性能方麵的巨大潛力,而且通過實證研究證明了其在資源受限環境中的適用性。研究者不僅關注模型的直接應用和性能評估,更深入探討了如何通過上下文學習增強LLM在非英語醫療環境中的能力,為全球數字醫療領域的發展提供了寶貴的見解和方法。
9月13日,吳賢博士將作客數智醫療分論壇,帶來題為“醫療大模型新進展及其應用”的主題報告,將分享更多關於如何將最新的人工智能技術與臨床醫療實踐相結合的前沿洞見。歡迎蒞臨現場,共同見證AI如何重塑我們的醫療與健康的未來。
參考文獻
WU J, WU X, QIU Z, et al. Large language models leverage external knowledge to extend clinical insight beyond language boundaries[J]. J Am Med Inform Assoc, 2024, 31(9): 2054-2064. DOI: 10.1093/jamia/ocae079.
編輯:梨九
二審:且行
三審:清揚
排版:耳東

 我要跟帖
我要跟帖
copyright©醫學論壇網 版權所有,未經許可不得複製、轉載或鏡像
京ICP證120392號 京公網安備110105007198 京ICP備10215607號-1 (京)網藥械信息備字(2022)第00160號



